
آپاچی اسپارک (Apache Spark) یک فریمورک پردازش داده توزیعشده و موتور محاسباتی برای کار با دادههای بزرگ (big data) است که برای اجرای موازی دادهها و تحلیلهای مقیاسپذیر طراحی شده است. هدف اصلی Spark فراهمآوردن پردازش سریع و جمعوجور با APIهای سطحبالا برای برنامهنویسان است؛ بهطوریکه عملیاتهای دستهای (batch)، پردازش جریانی (streaming)، پرسوجوهای تعاملی (SQL)، یادگیری ماشین (MLlib) و تحلیلهای گرافی (GraphX) را در یک پلتفرم یکپارچه ممکن میسازد. این ویژگیها باعث شده تا پرسش «آپاچی اسپارک چیست؟» پاسخ مشخصی داشته باشد: یک موتور واحد برای انواع بارهای کاری تحلیلی در محیطهای توزیعشده.
مزیت کلیدی Apache Spark نسبت به رویکردهای سنتی مبتنی بر MapReduce، بهرهگیری از پردازش درونحافظهای و اجرای موازی کارها است که در عمل بهطور چشمگیری زمان پردازش را کاهش میدهد. از اینرو Spark بهطور گسترده در تحلیل داده با آپاچی اسپارک، پیادهسازی جریانهای ETL، ساخت مدلهای ماشین لرنینگ با Spark و کارهای تحلیلی تعاملی استفاده میشود. همچنین Spark از زبانهای شناختهشدهای مانند Scala، جاوا، پایتون (PySpark) و R پشتیبانی میکند که توسعه و یکپارچهسازی را برای علوم داده و مهندسی داده سادهتر میسازد.
در ادامه این مطلب از وبلاگ آبالون بخش به بخش به معماری و اجزای Spark، مقایسهٔ Apache Spark با Hadoop، مزایا و محدودیتها، نمونههای کاربردی در علم داده و راهنمای ابتدایی اجرا و توسعه پرداخته خواهد شد.
معماری و اجزای آپاچی اسپارک
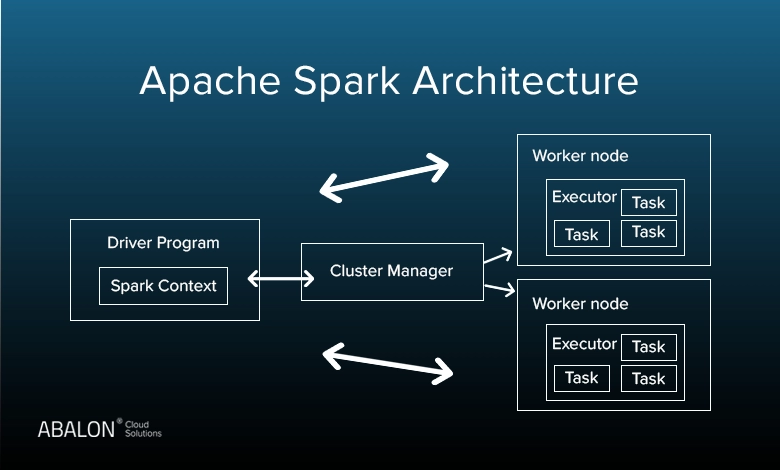
برای درک بهتر اینکه Apache Spark چیست و چگونه کار میکند، باید با معماری و اجزای اصلی آن آشنا شویم. اسپارک بر اساس یک معماری پردازش توزیعشده طراحی شده است که دادهها را در میان خوشهای (Cluster) از ماشینها پخش و پردازش میکند. این ساختار، امکان اجرای موازی دادهها را فراهم کرده و باعث افزایش چشمگیر سرعت پردازش میشود. در ادامه با بخشهای مختلف این ساختار آشنا خواهیم شد:
۱. Driver Program
برنامه Driver هسته مرکزی اجرای Spark است. این بخش وظیفه دارد برنامه شما را به تسکها (Tasks) کوچکتر تقسیم کرده و آنها را بین نودهای محاسباتی توزیع کند. همچنین وضعیت اجرا و مدیریت منابع توسط Driver کنترل میشود.
۲. Cluster Manager
مدیریتکننده خوشه (Cluster Manager) مسئول تخصیص منابع به Spark است. اسپارک میتواند با انواع سیستمهای مدیریت خوشه مانند Standalone ،Apache Mesos و Hadoop YARN کار کند.
۳. Executors
اجراکنندگان یا Executorها فرآیندهایی هستند که روی نودهای Worker اجرا میشوند و وظیفهٔ پردازش واقعی دادهها را بر عهده دارند. هر اجراکننده بخشی از داده را دریافت و محاسبات را انجام میدهد.
۴. RDD یا (Resilient Distributed Dataset)
RDD ساختار داده اصلی در Spark است. این دادهها به صورت توزیعشده و مقاوم در برابر خطا ذخیره میشوند. عملیات روی RDD به صورت موازی در کل خوشه انجام میشود.
۵. APIها و کتابخانهها
- Spark SQL برای پردازش دادههای ساختیافته با زبان SQL
- Spark Streaming برای پردازش دادههای جریانی در زمان واقعی
- MLlib برای ماشین لرنینگ با Spark
- GraphX برای تحلیل گرافها
معماری ماژولار آپاچی اسپارک باعث شده این پلتفرم بتواند بهراحتی در حوزههای متنوع مانند تحلیل داده، سیستمهای بلادرنگ، و پروژههای big data استفاده شود.
تفاوت Apache Spark با Hadoop

برای بسیاری از افراد که تازه وارد دنیای big data میشوند، این سوال پیش میآید که تفاوت اصلی Apache Spark و Hadoop چیست و در چه شرایطی هر کدام مناسبتر است. هر دو برای پردازش دادههای بزرگ در محیطهای توزیعشده طراحی شدهاند، اما رویکرد و عملکرد آنها تفاوتهای مهمی دارد.
۱. مدل پردازش
- Hadoop MapReduce دادهها را بهصورت دستهای (Batch) پردازش میکند. هر مرحله از پردازش نیازمند خواندن و نوشتن دادهها روی دیسک است.
- Apache Spark از پردازش درونحافظهای (In-Memory) استفاده میکند و دادهها را در RAM نگه میدارد. این کار باعث میشود اجرای موازی دادهها سریعتر و بهینهتر باشد.
۲. سرعت اجرا
- Spark در بسیاری از پردازشها تا ۱۰۰ برابر سریعتر از Hadoop عمل میکند، مخصوصاً در الگوریتمهای تکرارشونده مانند ماشین لرنینگ با Spark.
- دلیل این سرعت، کاهش عملیات I/O دیسک و ذخیره دادهها در حافظه موقت است.
۳. انعطافپذیری
- Hadoop عمدتاً برای پردازش دستهای طراحی شده است.
- Spark علاوه بر پردازش دستهای، پردازش جریانی (Real-Time Streaming)، تحلیل گراف و یادگیری ماشین را هم پشتیبانی میکند.
۴. سهولت توسعه
- Spark با پشتیبانی از زبانهای مختلف مثل اسکالا، جاوا، پایتون و R، یادگیری و پیادهسازی را برای علم داده و مهندسی داده سادهتر کرده است.
- Hadoop بیشتر بر Java متمرکز است و انعطاف کمتری دارد.
۵. کاربردها
- Hadoop بیشتر برای پردازشهای سنگین دستهای با حجم بسیار زیاد داده مناسب است.
- Spark برای پروژههایی که به سرعت بالا، تحلیل تعاملی، و پردازش بلادرنگ نیاز دارند، گزینه ایدهآل محسوب میشود.
مزایای آپاچی اسپارک چیست؟
محبوبیت روزافزون Apache Spark در حوزهی big data و تحلیل داده تصادفی نیست. این فریمورک مجموعهای از ویژگیها و قابلیتها را ارائه میدهد که آن را به یکی از قدرتمندترین ابزارهای پردازش داده در جهان تبدیل کرده است.
- سرعت بالا در پردازش دادهها: استفاده از پردازش درونحافظهای باعث شده Spark در مقایسه با سیستمهای سنتی مانند Hadoop MapReduce، تا چندین برابر سریعتر عمل کند. این ویژگی در اجرای موازی دادهها و الگوریتمهای تکرارشونده، مانند مدلهای ماشین لرنینگ با Spark، تأثیر ویژهای دارد.
- پشتیبانی از پردازش چندگانه: Spark تنها یک سیستم پردازش دستهای نیست؛ بلکه از پردازش جریانی (Streaming)، پردازش تعاملی (Interactive Queries) و تحلیل گراف نیز پشتیبانی میکند.
- یکپارچگی با ابزارهای big data: اسپارک بهخوبی با سیستمهایی مانند Hadoop YARN، دیتابیسهای NoSQL (مثل Cassandra و HBase) و حتی سیستمهای ابری مانند AWS و Azure سازگار است. در آبالون نیز استفاده از راهکارهای دوآپس این امکان را فراهم میکند که Spark و دیگر ابزارهای پردازش داده بهصورت مقیاسپذیر و خودکار در پروژههای واقعی بهکار گرفته شوند.
- مقیاسپذیری بالا: از لپتاپ شخصی تا خوشههای عظیم در دیتاسنترها، Spark میتواند بهراحتی متناسب با نیاز پروژه مقیاس بگیرد.
آبالون ارائهدهنده سرور ابری
سرور ابری آبالون، تمام امکانات یک سرور قدرتمند را روی محیط ابری و تنها در یک دقیقه در اختیارتان قرار میدهد. با خرید سرور ابری، هم از تهیه سختافزار فیزیکی بینیاز میشوید و هم در زمان و هزینه صرفهجویی میکنید.
کاربرد Apache Spark در علم داده
Apache Spark بهعنوان یکی از محبوبترین ابزارهای علم داده (Data Science)، نقش مهمی در جمعآوری، پردازش، تحلیل و مدلسازی دادهها ایفا میکند. قابلیتهای گستردهٔ آن در پردازش توزیعشده و اجرای موازی دادهها، به تیمهای داده امکان میدهد با حجم عظیمی از دادهها در زمان کوتاه کار کنند. در ادامه به برخی از اصلیترین کاربردهای آپاچی اسپارک در علم داده خواهیم پرداخت:
۱. پردازش و پاکسازی دادهها
پیش از انجام هر نوع تحلیل یا مدلسازی، دادهها باید پاکسازی و به شکل قابل استفاده درآیند. Spark با ابزارهایی مانند Spark SQL و RDDها، عملیات پیچیدهای مانند موارد زیر را به شکلی سریع و مقیاسپذیر انجام میدهد:
- حذف دادههای تکراری یا ناقص
- ترکیب دادهها از منابع مختلف (مثل دیتابیسها و فایلهای CSV یا JSON)
- تبدیل فرمت دادهها برای استفاده در مدلهای تحلیلی
۲. تحلیل دادههای بزرگ (Big Data Analytics)
با رشد بیوقفهٔ دادهها، تحلیل حجم عظیمی از اطلاعات به چالش اصلی سازمانها تبدیل شده است. Spark با توانایی پردازش big data با آپاچی اسپارک، به تحلیلگران این امکان را میدهد که:
- دادهها را روی خوشهای از صدها یا هزاران نود پردازش کنند.
- از الگوریتمها و کوئریهای پیچیده روی دادههای ساختیافته و غیرساختیافته استفاده کنند.
- تحلیلهای تجاری (Business Intelligence) و علمی را با سرعتی چندین برابر بیشتر نسبت به روشهای سنتی اجرا کنند.
۳. ماشین لرنینگ با Spark
کتابخانهٔ MLlib در Spark مجموعهای گسترده از الگوریتمهای یادگیری ماشین را فراهم میکند، از جمله:
- الگوریتمهای رگرسیون (Regression) برای پیشبینی مقادیر پیوسته
- الگوریتمهای طبقهبندی (Classification) برای دستهبندی دادهها
- الگوریتمهای خوشهبندی (Clustering) مانند K-Means
- سیستمهای پیشنهاددهنده (Recommendation Systems) برای پیشنهاد محتوا یا محصولات
مزیت اصلی این کتابخانه این است که تمام این الگوریتمها به صورت توزیعشده و موازی روی خوشهها اجرا میشوند، بنابراین حتی مجموعه دادههای چند ترابایتی هم قابل پردازش هستند.
۴. تحلیل دادههای جریانی
یکی از نقاط قوت Spark، امکان تحلیل دادههای جریانی با استفاده از Spark Streaming و Structured Streaming است. این قابلیت برای موارد زیر کاربرد دارد:
- پایش (Monitoring) لحظهای سیستمها و شبکهها
- تحلیل دادههای سنسورهای IoT
- پردازش و تحلیل جریانهای داده از شبکههای اجتماعی (مثل توییتها یا پستهای فیسبوک)
۵. تحلیل گرافها
با استفاده از کتابخانهٔ GraphX، اسپارک امکان مدلسازی و تحلیل شبکههای پیچیده را فراهم میکند. این کاربرد برای موارد زیر مفید است:
- تحلیل شبکههای اجتماعی (Social Network Analysis)
- مدلسازی روابط بین دادهها در سیستمهای توصیهگر
- بهینهسازی شبکههای حملونقل یا ارتباطات
۶. یکپارچهسازی با ابزارهای علم داده
Spark بهراحتی با ابزارهای متداول علم داده ترکیب میشود:
- اتصال به Jupyter Notebook برای توسعه و آزمایش کدهای تحلیلی
- هماهنگی با کتابخانههای بصریسازی داده مثل Matplotlib و Plotly
- استفاده در محیطهای ابری مانند AWS، گوگل کلود و Azure برای استقرار مدلها
- اتصال به دیتابیسهای NoSQL (مثل MongoDB و Cassandra) یا دیتابیسهای تحلیلی (مثل Amazon Redshift)
در پایان
پاسخ به پرسش «آپاچی اسپارک چیست؟» را میتوان اینگونه خلاصه کرد: Apache Spark یک فریمورک پردازش توزیعشده و سریع است که برای تحلیل دادههای بزرگ، پردازش جریانی، یادگیری ماشین، و تحلیل گرافها طراحی شده و به لطف پردازش درونحافظهای و اجرای موازی دادهها، سرعت و کارایی بالایی را ارائه میدهد.
در مقایسه با سیستمهایی مانند Hadoop MapReduce، اسپارک با کاهش نیاز به خواندن/نوشتن مکرر روی دیسک و پشتیبانی از بارهای کاری متنوع، یک راهکار همهجانبه برای تیمهای داده فراهم میکند. این فریمورک نهتنها برای شرکتهای فناوری بزرگ، بلکه برای استارتاپها و سازمانهای کوچکتر نیز بهدلیل انعطافپذیری، مقیاسپذیری، و پشتیبانی از زبانهای مختلف گزینهای ایدهآل محسوب میشود.








